14
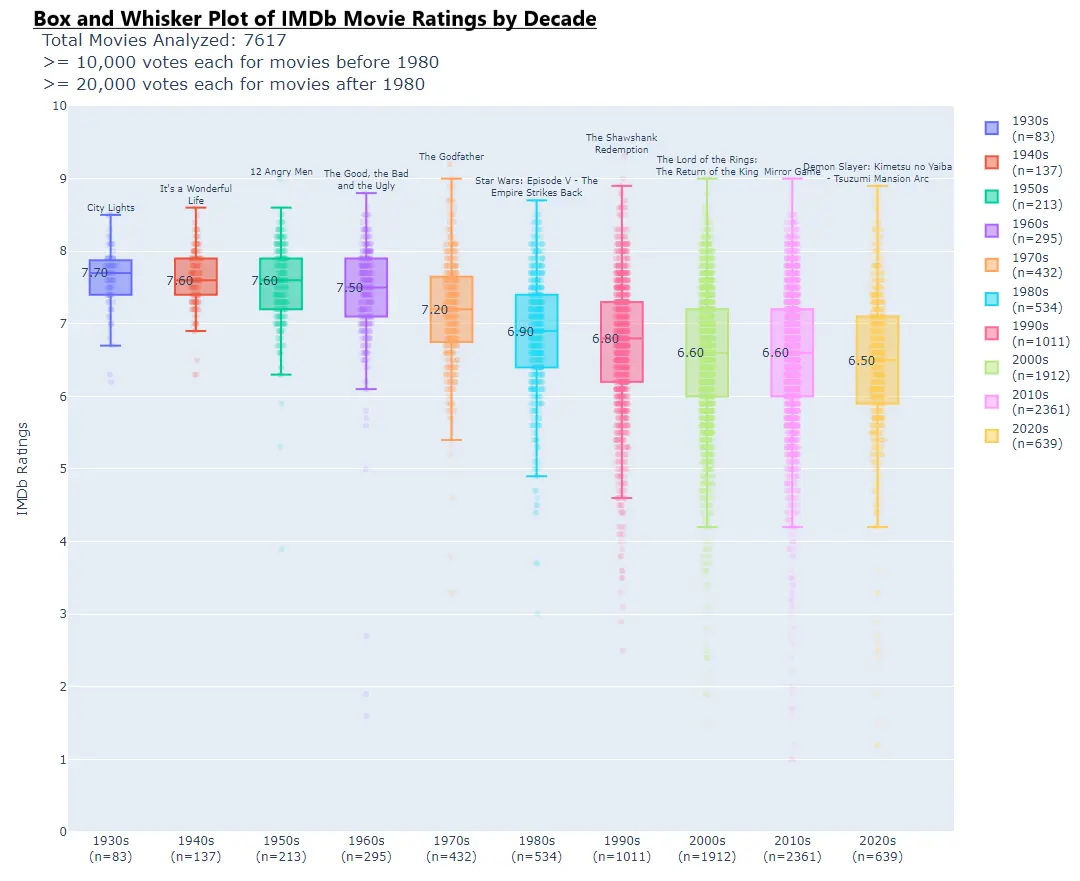
Which sampling bias do you think will be ignored by the RETVRN types?
- Worse movies are less likely to survive and be distributed.
- Only 'classics' will overcome a preference for watching newer movies.
Which sampling bias do you think will be ignored by the RETVRN types?
I would love to see this overlaid with the volume of movies per decade.
If you look to the bar on the right you see the number of movies of each decade
I had no idea of what that bar was trying to say. Number of reviews? People polled?
Thanks for letting me know.
Number of movies for each decade. On the top there’s the threshold for reviews that they used
Wow. I am blind.
I don't like the horizontal bar graphs (or I guess rather plot points) running along the box and whiskers. They don't have units and don't really help convey much of anything that the box and whiskers didn't already convey. Yes, they are more granular, but that granularity isn't all that useful.
They used Demon Slayer as the last one? That seems like it would skew the data as it’s not something everyone would watch.
These numbers are from analyzing over 7000 movies, the title at the top is probably the highest rated title in each bucket.
I wonder if that considers number of ratings. Either it doesn’t, or Demon Slayer is much more popular than I thought!
A place to share and discuss data visualizations. #dataviz
(under new moderation as of 2024-01, please let me know if there are any changes you want to see!)