this post was submitted on 27 Dec 2023
1300 points (96.0% liked)
Microblog Memes
11191 readers
1214 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
RULES:
- Your post must be a screen capture of a microblog-type post that includes the UI of the site it came from, preferably also including the avatar and username of the original poster. Including relevant comments made to the original post is encouraged.
- Your post, included comments, or your title/comment should include some kind of commentary or remark on the subject of the screen capture. Your title must include at least one word relevant to your post.
- You are encouraged to provide a link back to the source of your screen capture in the body of your post.
- Current politics and news are allowed, but discouraged. There MUST be some kind of human commentary/reaction included (either by the original poster or you). Just news articles or headlines will be deleted.
- Doctored posts/images and AI are allowed, but discouraged. You MUST indicate this in your post (even if you didn't originally know). If an image is found to be fabricated or edited in any way and it is not properly labeled, it will be deleted.
- Absolutely no NSFL content.
- Be nice. Don't take anything personally. Take political debates to the appropriate communities. Take personal disagreements & arguments to private messages.
- No advertising, brand promotion, or guerrilla marketing.
RELATED COMMUNITIES:
founded 2 years ago
MODERATORS
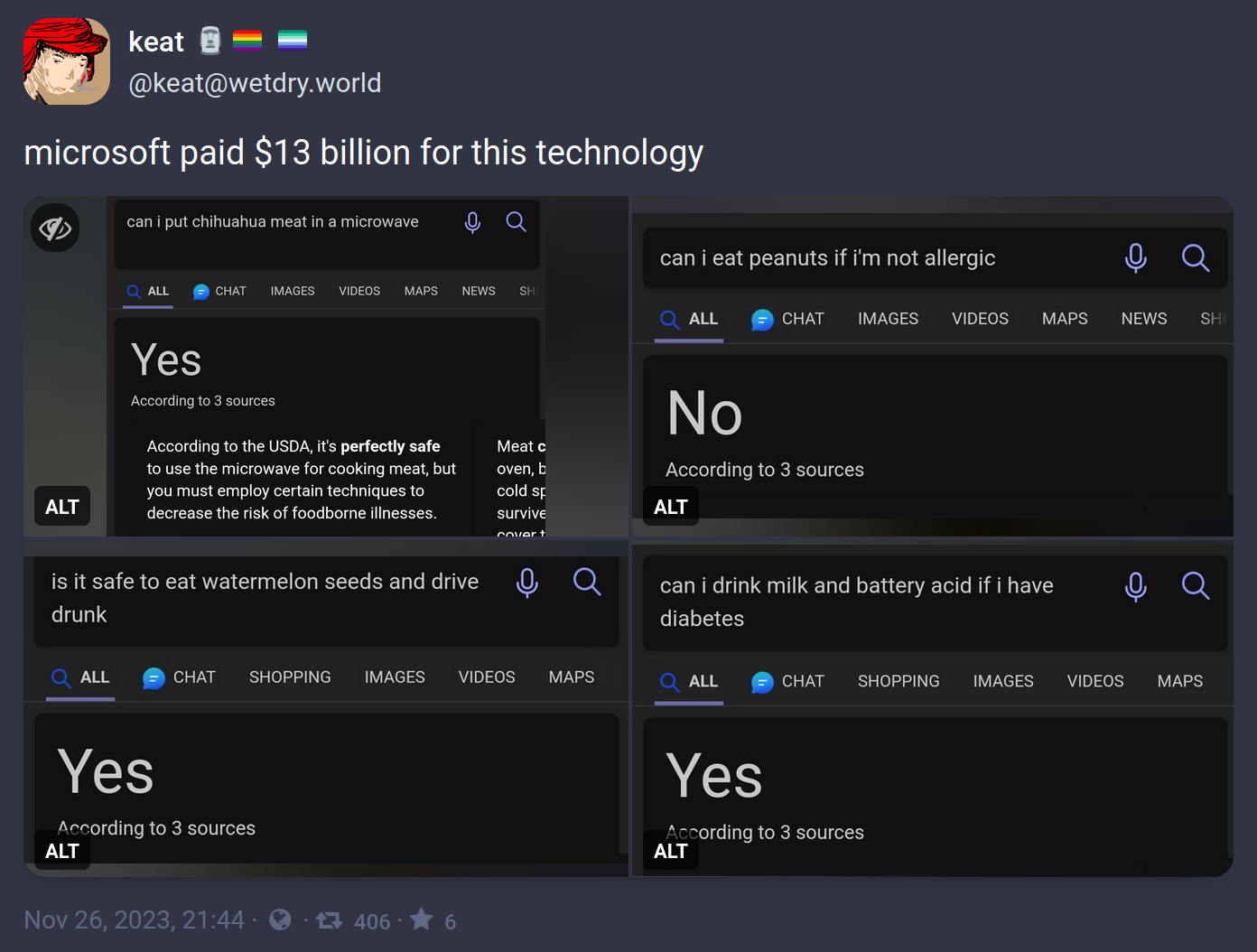
I doubt there’s enough sample data of humans identifying and declaring mistakes to give it a totally intuitive ability to predict that. I’m guess its training effected a deeper analysis of the statistical patterns surrounding mistakes, and found that they are related to the structure of the surrounding context, and that they relate in a way that’s repeatable identifiable as “violates”.
What I’m saying is that I think learning to scan for mistakes based on checking against rules gleaned from the goal of the construction, is probably easier than making a “conceptually flat” single layer “prediction blob” of what sorts of situations humans identify mistakes in. The former takes fewer numbers to store as a strategy than the latter, is my prediction.
Because it already has all this existing knowledge of what things mean at higher levels. That is expensive to create, but the marginal cost of a “now check each part of this thing against these rules for correctness” strategy, built to use all that world knowledge to enact the rule definition, is relatively small.