4
Does DeepSeek* Solve the Small Scale Model Performance Puzzle?
(community.intel.com)
Just putting this here because I found this useful:
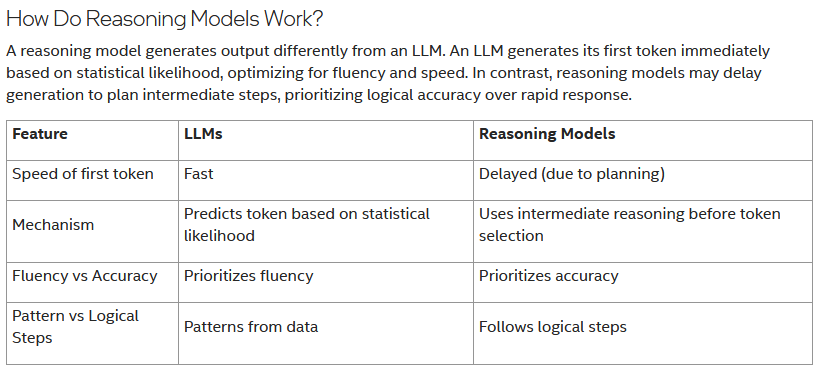
Well, I think 1) is correct, while 2) 3) and 4) are mostly misleading. The Reasoning Models are still LLMs. Just that they emulate some inner dialogue before writing the final text. I wouldn't use the word "accuracy" in context with AI. It's far from accurate these days, no matter what we do. And in 2), it uses intermediate reasoning. But the Mechanism is still predicting tokens based on statistical likelihood. And regarding 4) also the patterns still come from data, so do the intermediary "logical" steps. And if we look for example at the "thinking" steps of Deepseek R1, it's often unalike human reasoning. I had it reason very illogical steps and outright false things, and despite that, it sometimes arrives at a correct conclusion... Make of this what you will, but I don't think "logical" or "accuracy" are the right words here. Table rows 2, 3 and 4 are oversimplified to the point where it's not correct any more. IMO