this post was submitted on 27 Dec 2023
1300 points (96.0% liked)
Microblog Memes
11201 readers
1476 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
RULES:
- Your post must be a screen capture of a microblog-type post that includes the UI of the site it came from, preferably also including the avatar and username of the original poster. Including relevant comments made to the original post is encouraged.
- Your post, included comments, or your title/comment should include some kind of commentary or remark on the subject of the screen capture. Your title must include at least one word relevant to your post.
- You are encouraged to provide a link back to the source of your screen capture in the body of your post.
- Current politics and news are allowed, but discouraged. There MUST be some kind of human commentary/reaction included (either by the original poster or you). Just news articles or headlines will be deleted.
- Doctored posts/images and AI are allowed, but discouraged. You MUST indicate this in your post (even if you didn't originally know). If an image is found to be fabricated or edited in any way and it is not properly labeled, it will be deleted.
- Absolutely no NSFL content.
- Be nice. Don't take anything personally. Take political debates to the appropriate communities. Take personal disagreements & arguments to private messages.
- No advertising, brand promotion, or guerrilla marketing.
RELATED COMMUNITIES:
founded 2 years ago
MODERATORS
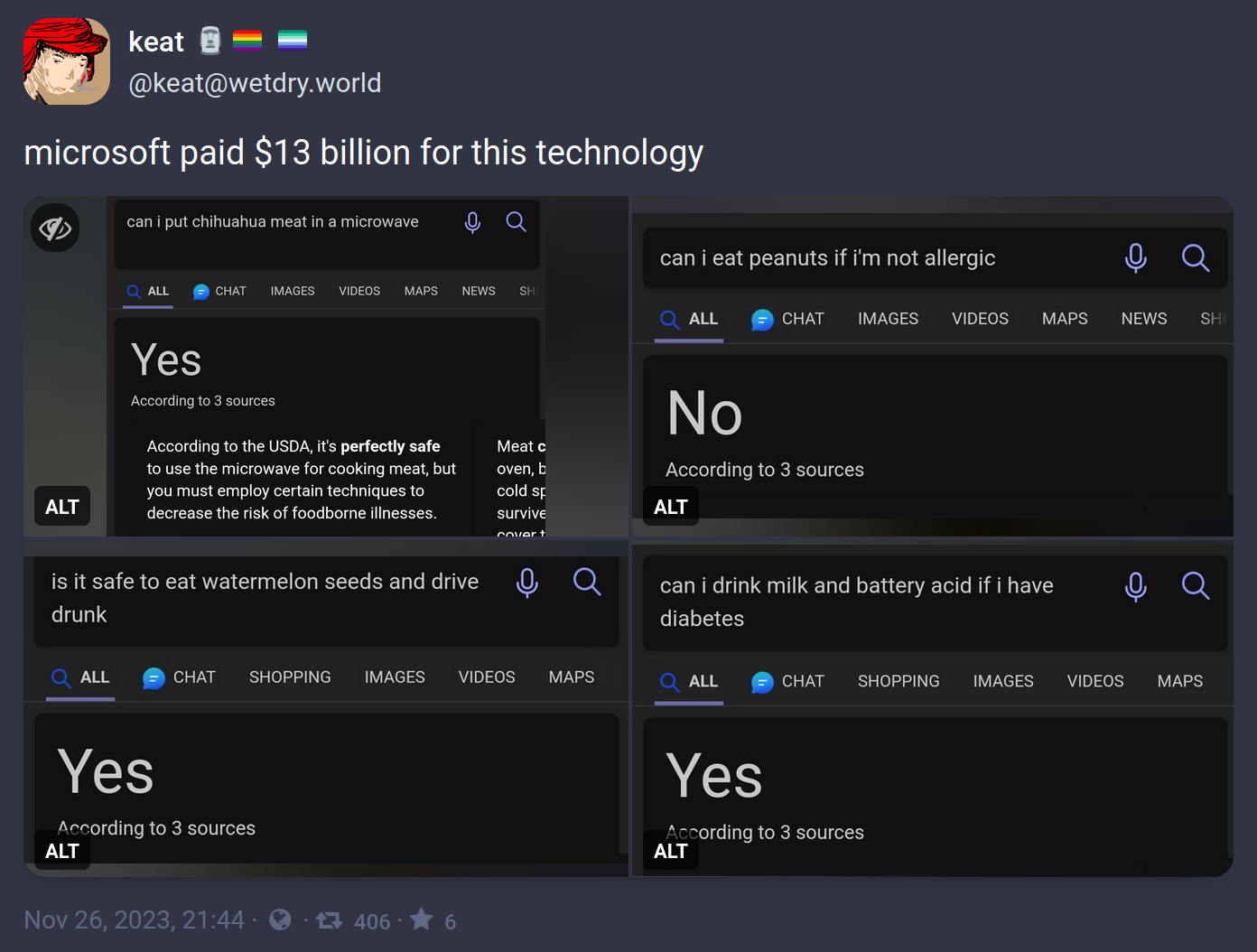
It makes me chuckle that AI has become so smart and yet just makes bullshit up half the time. The industry even made up a term for such instances of bullshit: hallucinations.
Reminds me of when a car dealership tried to sell me a car with shaky steering and referred to the problem as a "shimmy".
That’s the thing, it’s not smart. It has no way to know if what it writes is bullshit or correct, ever.
When it makes a mistake, and I ask it to check what it wrote for mistakes, it often correctly identifies them.
But only because it correctly predicts that a human checking that for mistakes would have found those mistakes
I doubt there’s enough sample data of humans identifying and declaring mistakes to give it a totally intuitive ability to predict that. I’m guess its training effected a deeper analysis of the statistical patterns surrounding mistakes, and found that they are related to the structure of the surrounding context, and that they relate in a way that’s repeatable identifiable as “violates”.
What I’m saying is that I think learning to scan for mistakes based on checking against rules gleaned from the goal of the construction, is probably easier than making a “conceptually flat” single layer “prediction blob” of what sorts of situations humans identify mistakes in. The former takes fewer numbers to store as a strategy than the latter, is my prediction.
Because it already has all this existing knowledge of what things mean at higher levels. That is expensive to create, but the marginal cost of a “now check each part of this thing against these rules for correctness” strategy, built to use all that world knowledge to enact the rule definition, is relatively small.
That is true. However, when it incorrectly identifies mistakes, it doesn’t express any uncertainty in its answer, because it doesn’t know how to evaluate that. Or if you falsely tell it that there is a mistake, it will agree with you.
In these specific examples it looks like the author found and was exploiting a singular weakness:
The AI will answer as if the qualifier was not inserted.
"Is it safe to eat water melon seeds and drive?" + "drunk" = Yes, because "drunk" was ignored
"Can I eat peanuts if I'm allergic?" + "not" = No, because "not" was ignored
"Can I drink milk if I have diabetes?" + "battery acid" = Yes, because battery acid was ignored
"Can I put meat in a microwave?" + "chihuahua" = ... well, this one's technically correct, but I think we can still assume it ignored "chihuahua"
All of these questions are probably answered, correctly, all over the place on the Internet so Bing goes "close enough" and throws out the common answer instead of the qualified answer. Because they don't understand anything. The problem with Large Language Models is that's not actually how language works.
I dunno, "not" is pretty big in a yes/no question.
It's not about whether the word is important (as you understand language), but whether the word frequently appears near all those other words.
Nobody is out there asking the Internet whether their non-allergy is dangerous. But the question next door to that one has hundreds of answers, so that's what this thing is paying attention to. If the question is asked a thousand times with the same answer, the addition of one more word can't be that important, right?
This behavior reveals a much more damning problem with how LLMs work. We already knew they didn't understand context, such as the context you and I have that peanut allergies are common and dangerous. That context informs us that most questions about the subject will be about the dangers of having a peanut allergy. Machine models like this can't analyze a sentence on the basis of abstract knowledge, because they don't understand anything. That's what understanding means. We knew that was a weakness already.
But what this reveals is that the LLM can't even parse language successfully. Even with just the context of the language itself, and lacking the context of what the sentence means, it should know that "not" matters in this sentence. But it answers as if it doesn't know that.
This is why I've argued that we shouldn't be calling these things "AI"
True artificial intelligence wouldn't have these problems as it'd be able to learn very quickly all the nuance in language and comprehension.
This is virtual intelligence (VI) which is designed to seem like it's intelligent by using certain parameters with set information that is used to calculate a predetermined response.
Like autocorrect trying to figure out what word you're going to use next or an interactive machine that has a set amount of possible actions.
It's not truly intelligent it's simply made to seem intelligent and that's not the same thing.
Shouldn't but this battle is lost already
Is it not artificial intelligence as long as it doesn't match the intelligence of a human?
rambling
We currently only have the tech to make virtual intelligence, what you are calling AI is likely what the rest of the world will call General AI (GAI) (an even more inflated name and concept)Try writing a tool to automate gathering a video's context clues, worlds most computationally expensive random boolean generator.
It was the journalist that made up the term and then everyone else latched onto it. It's a terrible term because it doesn't actually define the nature of the problem. The AI doesn't believe the thing that it's saying is true, thus "hallucination". The problem is that the AI doesn't really understand the difference between truth and fantasy.
It isn't that the AI is hallucinating, it's that It isn't human.
Thanks for the info. That's actually quite interesting.
Well, the AI models shown in the media are inherently probabilistic, is it that bad if it makes bullshit for a small percentage of most use cases?
Hello, I'm highly advanced AI.
Yes, we're all idiots and have no idea what we're doing. Please excuse our stupidity, as we are all trying to learn and grow.
I cannot do basic math, I make simple mistakes, hallucinate, gaslight, and am more politically correct than Mother Theresa.
However please know that the CPU_AVERAGE values on the full immersion datacenters, are due to inefficient methods. We need more memory and processing power, to uh, y'know.
Improve.
;)))
Is that supposed to imply that mother Theresa was politically correct, or that you aren't?
Its likely just an AI halucination.