this post was submitted on 27 Dec 2023
1300 points (96.0% liked)
Microblog Memes
11201 readers
1223 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
RULES:
- Your post must be a screen capture of a microblog-type post that includes the UI of the site it came from, preferably also including the avatar and username of the original poster. Including relevant comments made to the original post is encouraged.
- Your post, included comments, or your title/comment should include some kind of commentary or remark on the subject of the screen capture. Your title must include at least one word relevant to your post.
- You are encouraged to provide a link back to the source of your screen capture in the body of your post.
- Current politics and news are allowed, but discouraged. There MUST be some kind of human commentary/reaction included (either by the original poster or you). Just news articles or headlines will be deleted.
- Doctored posts/images and AI are allowed, but discouraged. You MUST indicate this in your post (even if you didn't originally know). If an image is found to be fabricated or edited in any way and it is not properly labeled, it will be deleted.
- Absolutely no NSFL content.
- Be nice. Don't take anything personally. Take political debates to the appropriate communities. Take personal disagreements & arguments to private messages.
- No advertising, brand promotion, or guerrilla marketing.
RELATED COMMUNITIES:
founded 2 years ago
MODERATORS
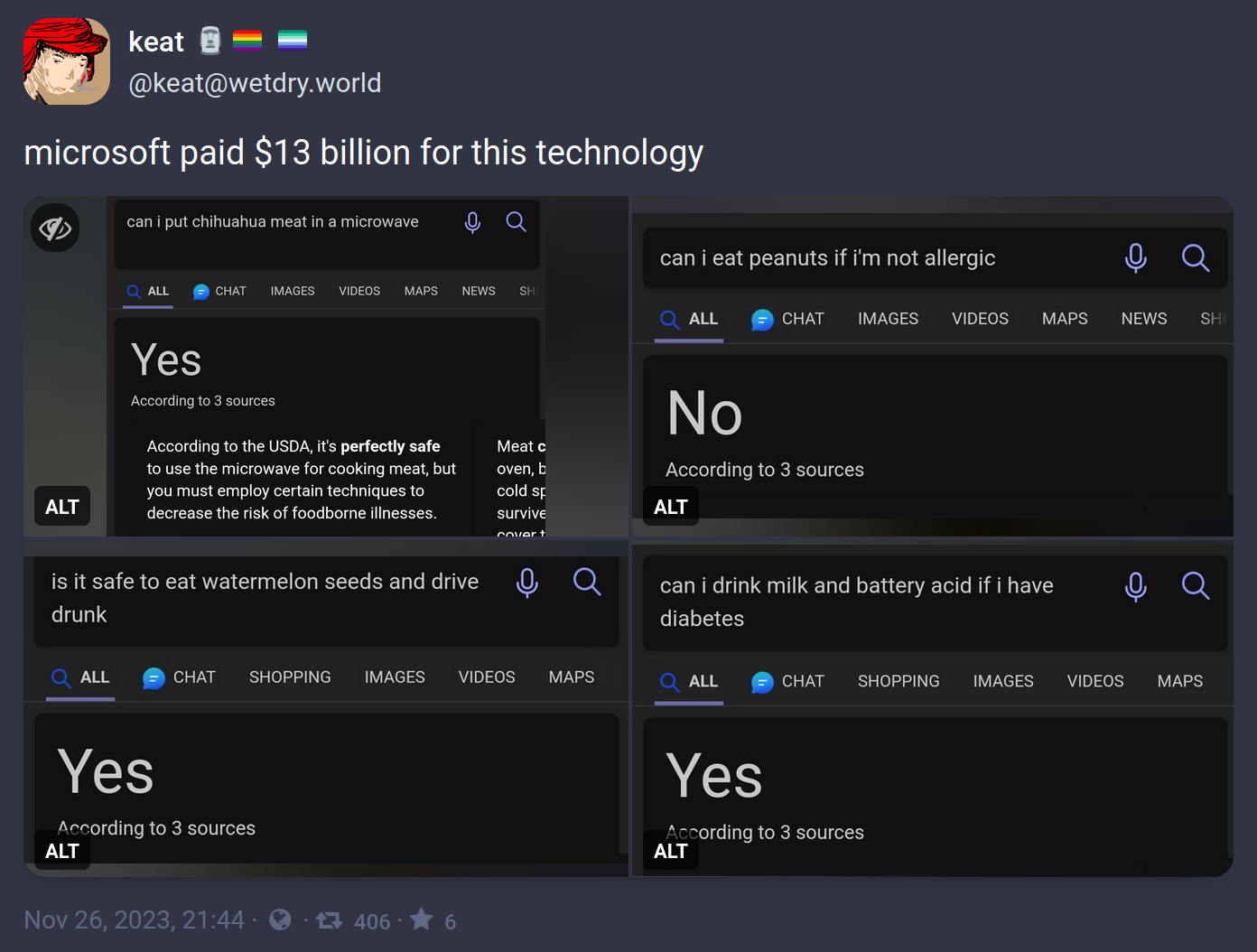
Generative AI is INCREDIBLY bad at mathmatical/logical reasoning. This is well known, and very much not surprising.
That's actually one of the milestones on the way to general artificial intelligence. The ability to reason about logic & math is a huge increase in AI capability.
Well known by you, not everybody.
Well known by everyone that knows anything about LLMs at all
It's not. This is already obsolete.
I've used gpt4 enough in the past months to confidently say the improvements in this blog post aren't noteworthy
They aren't live in the consumer model. This is a research post, not in production.
There's other literature elsewhere on getting improved math performance with GPT-4 as it exists right now.
It's really not in the most current models.
And it's already at present incredibly advanced in research.
The bigger issue is abstract reasoning that necessitates nonlinear representations - things like Sodoku, where exploring a solution requires updating the conditions and pursuing multiple paths to a solution. This can be achieved with multiple calls, but doing it in a single process is currently a fool's errand and likely will be until a shift to future architectures.
I'm referring to models that understand language and semantics, such as LLMs.
Other models that are specifically trained can't do what it can, but they can perform math.
The linked research is about LLMs. The opening of the abstract of the paper: