I've started encountering a problem that I should use some assistance troubleshooting. I've got a Proxmox system that hosts, primarily, my Opnsense router. I've had this specific setup for about a year.
Recently, I've been experiencing sluggishness and noticed that the IO wait is through the roof. Rebooting the Opnsense VM, which normally only takes a few minutes is now taking upwards of 15-20. The entire time my IO wait sits between 50-80%.
The system has 1 disk in it that is formatted ZFS. I've checked dmesg, and the syslog for indications of disk errors (this feels like a failing disk) and found none. I also checked the smart statistics and they all "PASSED".
Any pointers would be appreciated.
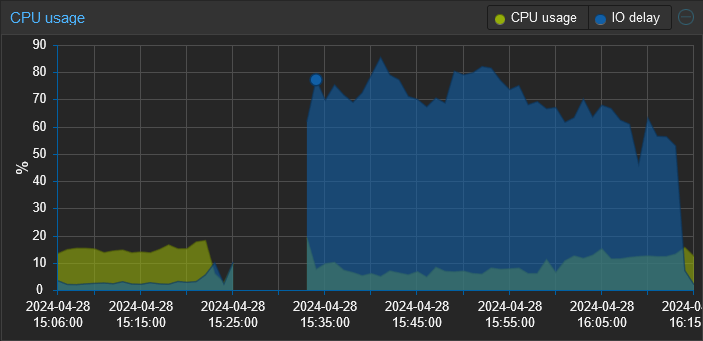
Edit: I believe I've found the root cause of the change in performance and it was a bit of shooting myself in the foot. I've been experimenting with different tools for log collection and the most recent one is a SIEM tool called Wazuh. I didn't realize that upon reboot it runs an integrity check that generates a ton of disk I/O. So when I rebooted this proxmox server, that integrity check was running on proxmox, my pihole, and (I think) opnsense concurrently. All against a single consumer grade HDD.
Thanks to everyone who responded. I really appreciate all the performance tuning guidance. I've also made the following changes:
- Added a 2nd drive (I have several of these lying around, don't ask) converting the zfs pool into a mirror. This gives me both redundancy and should improve read performance.
- Configured a 2nd storage target on the same zpool with compression enabled and a 64k block size in proxmox. I then migrated the 2 VMs to that storage.
- Since I'm collecting logs in Wazuh I set Opnsense to use ram disks for /tmp and /var/log.
Rebooted Opensense and it was back up in 1:42 min.
iowait is indicative of storage not being able to keep up with the performance of the rest of the system. What hardware are you using for storage here?
It's an old Optiplex SFF with a single HDD. Again, my concern isn't that it's "slow". It's that performance has rather suddenly tanked and the only changes I've made are regular OS updates.
If I had to guess there was a code change in the PVE kernel or in their integrated ZFS module that led to a performance regression for your use case. I don't really have any feedback there, PVE ships a modified version of an older kernel (6.2?) so something could have been backported into that tree that led to the regression. Same deal with ZFS, whichever version the PVE folks are shipping could have introduced a regression as well.
Your best bet is to raise an issue with the PVE folks after identifying which kernel version introduced the regression, you'll want to do a binary search between now and the last known good time that this wasn't occurring to determine exactly when the issue started - then you can open an issue describing the regression.
Or just throw a cheap SSD at the problem and move on, that's what I'd do here. Something like this should outlast the machine you put it in.
Edit: the Samsung 863a also pops up cheaply from time to time, it has good endurance and PLP. Basically just search fleaBay for SATA drives with capacities of 400/480gb, 800/960gb, 1.6T/1.92T or 3.2T/3.84T and check their datasheets for endurance info and PLP capability. Anything in the 400/800/1600/3200Gb sequence is a model with more overprovisioning and higher endurance (usually refered to as mixed use) model. Those often have 3 DWPD or 5 DWPD ratings and are a safe bet if you have a write heavy workload.
I thought cheap SSDs and ZFS didn't play well together?
Keep in mind it's more an issue with writes as others mentioned when it comes to ssds. I use two ssds in a zfs mirror that I installed proxmox directly on. It's an option in the installer and it's quite nice.
As for combating writes that's actually easier than you think and applies to any filesystem. It just takes knowing what is write intensive. Most of the time for a linux os like proxmox that's going to be temp files and logs. Both of which can easily be migrated to tmpfs. Doing this will increase the lifespan of any ssd dramatically. You just have to understand restarting clears those locations because now they exist in ram.
As I mentioned elsewhere opnsense has an option within the gui to migrate tmp files to memory.
Depends on the SSD, the one I linked is fine for casual home server use. You're unlikely to see enough of a write workload that endurance will be an issue. That's an enterprise drive btw, it certainly wasn't cheap when it was brand new and I doubt running a couple of VMs will wear it quickly. (I've had a few of those in service at home for 3-4y, no problems.)
Consumer drives have more issues, their write endurance is considerably lower than most enterprise parts. You can blow through a cheap consumer SSD's endurance in mere months with a hypervisor workload so I'd strongly recommend using enterprise drives where possible.
It's always worth taking a look at drive datasheets when you're considering them and comparing the warranty lifespan to your expected usage too. The drive linked above has an expected endurance of like 2PB (~3 DWPD, OR 2TB/day, over 3y) so you shouldn't have any problems there. See https://www.sandisk.com/content/dam/sandisk-main/en_us/assets/resources/enterprise/data-sheets/cloudspeed-eco-genII-sata-ssd-datasheet.pdf
Older gen retired or old stock parts are basically the only way I buy home server storage now, the value for your money is tremendous and most drives are lightly used at most.
Edit: some select consumer SSDs can work fairly well with ZFS too, but they tend to be higher endurance parts with more baked in over provisioning. It was popular to use Samsung 850 or 860 Pros for a while due to their tremendous endurance (the 512GB 850s often had an endurance lifespan of like 10PB+ before failure thanks to good old high endurance MLC flash) but it's a lot safer to just buy retired enterprise parts now that they're available cheaply. There are some gotchas that come along with using high endurance consumer drives, like poor sync write performance due to lack of PLP, but you'll still see far better performance than an HDD.
Thanks for all the info. I'll keep this in mind if I replace the drive. I am using refurb enterprise HDDs in my main server. Didn't think I'd need to go enterprise grade for this box but you make a lot of sense.
Quick and easy fix attempt would be to replace the HDD with an SSD. As others have said, the drive may just be failing. Replacing with an SSD would not only get rid of the suspect hardware, but would be an upgrade to boot. You can clone the drive, or just start fresh with the backups you have.
I may end up having to go that route. I'm no expert but aren't you supposed to use different parameters when using SSDs on ZFS vs an HDD?
That's what I'd do here, used enterprise SSDs are dirt cheap on fleaBay