1
7
Suggest improvements to my IPv4 ping census program
(github.com)
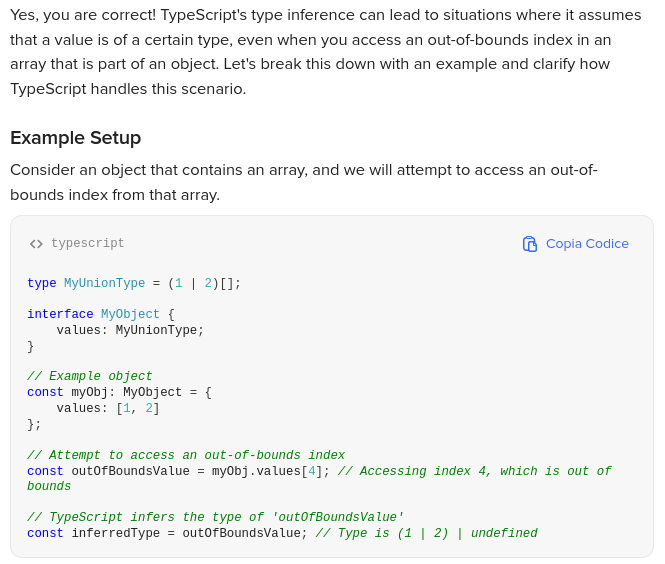 TypeScript does not throw an error at compile time for accessing an out-of-bounds index. Instead, it assumes that the value could be one of the types defined in the array (in this case, 1 or 2) or undefined.
TypeScript does not throw an error at compile time for accessing an out-of-bounds index. Instead, it assumes that the value could be one of the types defined in the array (in this case, 1 or 2) or undefined.
TypeScript automatically infers the type of a value accessed from an array, even if that access is out of bounds. It assumes that the value could be one of the defined types or undefined, which can lead to confusion if you expect stricter enforcement of valid indices.
I just spent the last 2 hours trying to understand why I was getting a valid type from something that shouldn't have been valid.
I think that the hate that JavaScript receives is well deserved, at least coming from Rust this is an absolute nightmare.
All things programming and coding related. Subcommunity of Technology.
This community's icon was made by Aaron Schneider, under the CC-BY-NC-SA 4.0 license.

