Paperlessngx will store pdfs and index their contents for searching. It's not necessarily meant for books but I think it would work.
What cad software did you use?
I might be naive, but given how often its being done I have to imagine that of all the project initiatives at Proton, adding LLMs is a relatively easy integration, when you compare it do developing a native application. Im sure theres been work at proton for a long time on those features, its just that the LLM team did this project quickly.
10 GB of a database table sounds like a lot of records. Of course if this contained pictures or other media then this wouldnt be much. But I dont know for certain what data was leaked.
What GPU are you using to run it? And what UI are you using to interface with it? (I know of gpt4all and the generic sounding ui-text-generation program or something)
Are these complaints about the free tier? I can see how they might start witholding options for that. Removing the delete option doesn't seem right.
Can a frequent Kdenlive user comment on the speed performance of this update? The marketing makes it sound incredible, plus the Qt6 update.
I've done project rewrites. This minimizes the problem solving to mostly just syntax, sometimes a new paradigm if the framework is different enough. But in my experience a rewrites goes so much faster than I expect it, since theres a very clear goal to achieve while rewriting. If someone has an existing project to rewrite, I recommend it. If not, you could implement some project in a framework your comfortable with, and then do a rewrite in the new thing.
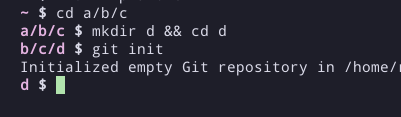
When I hopped on the home manager train I enabled starship (since it was just a couple lines to add) and I'm very happy with it. It has a couple small things out of the box that I really want. Mostly, its trimming my path so it doesnt take the full width of my terminal. I have it set so it only prints the lowest 3 directories and it wont print any directory higher than the current git repo Im in. IMO i hate all the little emojis but that was very easy to remove/disable. Its a very clean experience, and straightforward config (toml if not using nix).
EDIT: here's a pic of the path trimming. This is about as complicated as it gets. Also, I'm using catpuccin color scheme in urxvt.
rutrum
joined 2 years ago
Its a paradigm shift from pandas. In polars, you define a pipeline, or a set of instructions, to perform on a dataframe, and only execute them all at once at the end of your transformation. In other words, its lazy. Pandas is eager, which every part of the transformation happens sequentially and in isolation. Polars also has an eager API, but you likely want to use the lazy API in a production script.
Because its lazy, Polars performs query optimization, like a database does with a SQL query. At the end of the day, if you're using polars for data engineering or in a pipeline, it'll likely work much faster and more memory efficient. Polars also executes operations in parallel, as well.