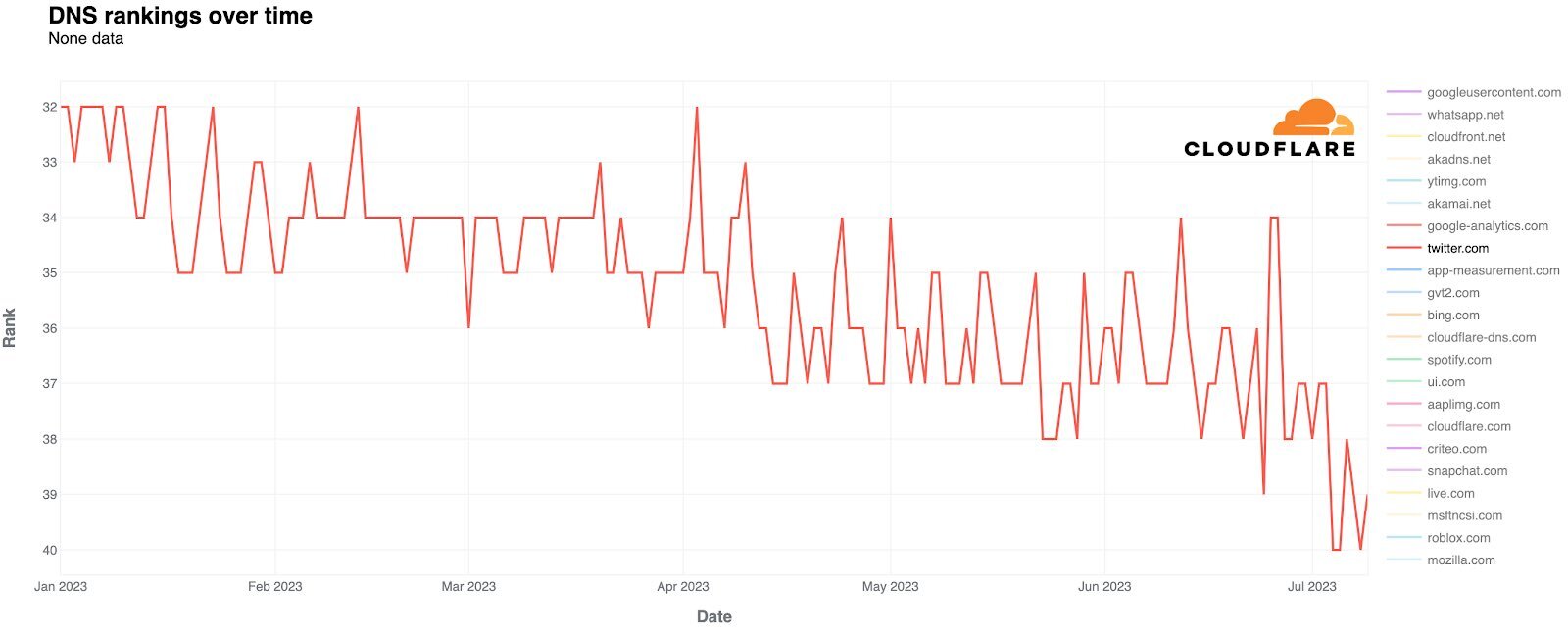
I am not one for policies restricting choice but I fear the situation where Meta sets up instances that become big, say like Lemmy.world. Then one day when their instance is popular, they decide to charge other instances to federate with Meta's instances.
Big corps like YouTube, twitter, Meta, etc are known to offer services at a loss to grow their service and then drop the hammer and demand payment to use what people already rely on.
I feel a policy that prevents federated corp instance from profiting early on from FOSS, self hosted, and volunteer federated servers is something to think about - though I do not know the best approach.
I like what Open Source software does with their licensing approach where you are free to view, use, and contribute but if you take you must distribute the source code to others. Some outright ban usage for profit without a license.
Obviously licensing applies well for software to prevent abuse, and I would like a discussion about what Terms of Use policies can prevent volunteer work from being abused - if any are desired.
see the following cross-post from: https://programming.dev/post/427323
Should programming.dev defederate from Meta if they implement ActivityPub?
I'm not suggesting anything, just want to know what do you think.
Here is a link if someone don't know what Meta's Threads is: https://blog.joinmastodon.org/2023/07/what-to-know-about-threads/
Recently I used Google maps to search for the nearest DHL near me so I could return a package. DHL is not that popular near me and when I specifically typed for DHL, I would get only their competitors in the search results.
There was a DHL service center near me and I had to scroll a bunch to find it. Oh, and apparently big box stores (or anyone) can pay Google to come up in the search on maps, even if unrelated.
I don't think they have skin the in shipping game but their algorithms are over optimized that they don't even show what your searching for, but trying to infer why you're searching for it. That or whoever pays them more. Certainly a search risk