64
I'm curious why he still carry all those things after he is done with it.
I'm curious why he still carry all those things after he is done with it.
(Rant)
At somepoint, HSBC decided KDE Connect installed via F-Droid is less secure.
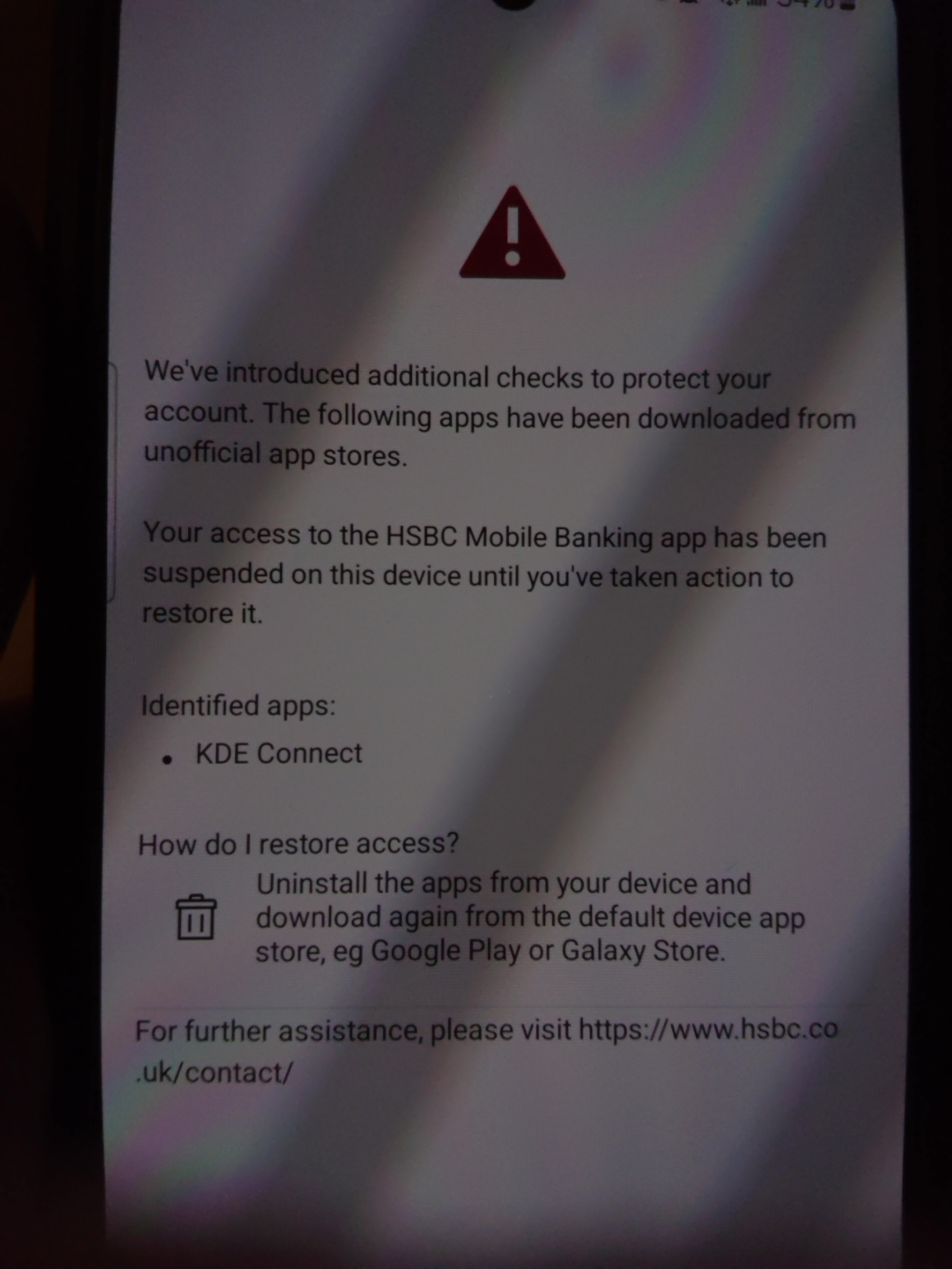
Then it decide non-whitelisted keyborads are a security risk. Only Gboard and Samsung Keyboard is confirmed within the whitelist.
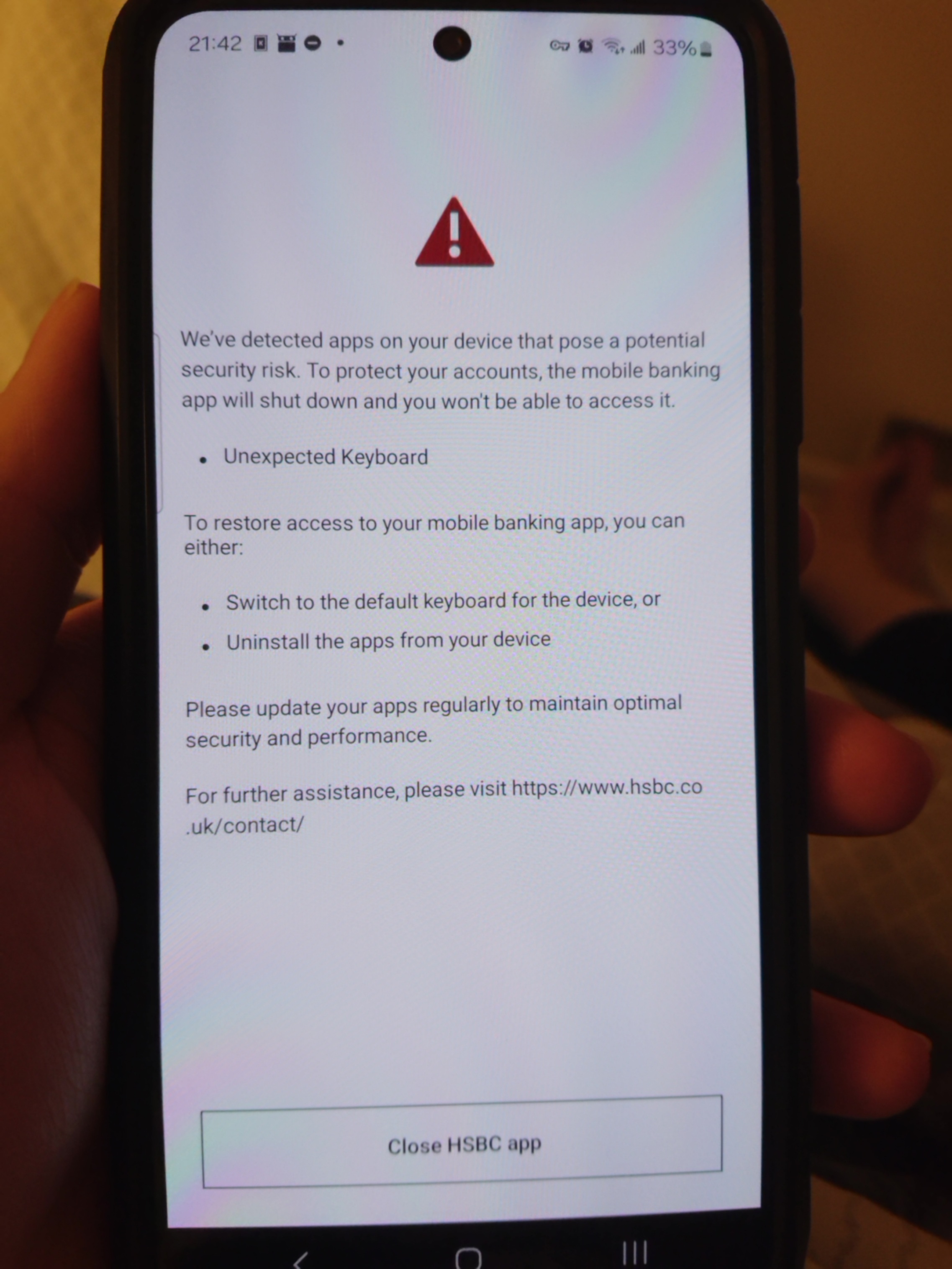
I understand the point that risk can be introduce at various points, yet this is simply too much. Yeah there are people phone infected by malware but from Play Store. Not a single time I heard one ever happened on F-Droid distributed apps, at least not from the official repo. Also, I will put more trust on an open source keyboard than any proprietary keyboard.
Furthermore, I'm shocked that an app can read my app list, and current keyboard (introduced in Android 14). This just make building a profile much easier as I belive everyone almost have an unique set of apps they like. I don't think any apps need such functionality. Why the f it needs to care what input devices I uses? This make me worry more about untold (aka burried deep in Privacy Policy) data collection.
Reverting to RAM sticks is good, but not shutting down GPU line. GPU market needs more competiter, not less.
the document is nearly impossible to read all the way through and just as hard to understand fully
It is a boring document but it not impossible to read through, nor understand. The is what compliances officer do. I have a (useless) cybersecurity degree and reading NIST publications is part of my lecture.
They all are free, no subscription required
And sorry Apple users, I don't know what option you have cuz I don't use Apple.
Easiest solution: point the fucking DNS to a family safe one and lock it behind passcode. Done.
This is how you "protect the children." Not by making a burden on everyone else. I don't need age verification on the internet, ever.
Which also gives them another idea on how to deny FOIA request?
The only blocker to me is it doesn't have native Linux support
Until they ditch the "live service" model, this will continues. How many big title games today are really sold in a complete no BS state where DLC actually means extra contents? No much I guess.
That stems from the revenue model, and not by gamers.
It's a invented problem to justify always online DRM.
"trying"
Nice try, Apple.
I don't get it. Why I need cloud to run Python scripts which can be done locally? Installing Python isn't hard and MS can bundle it as a library with Office either.
In the end, only the customer pays extras.