163
It's nice to see that he's already traking a principled stand.
It's nice to see that he's already traking a principled stand.
Edit: I figured it out. The problem wasn't permissions or Firefox itself, but my launcher. I'm using OLauncher, 'cause I rather like it's text-lookup interface, but as it doesn't make use of a traditional "home screen" Firefox won't allow me to create an entry there.
Apparently, it's a much-desired feature request
I think it may have been renamed to "Install" in previous versions, but neither appear anymore, and I don't see any permissions denied so I'm assuming that can't be it.


This is nowhere near the average Debian update experience. Debian is favoured precisely for its stability and simplicity, so if youre getting stuff like this, it's far from average.
Those errors look like file corruption. Maybe they were partially downloaded or written to a flakey disk, it's hard to say. I'd also echo the other comment or that Kali (and honestly Debian) are not well suited for gaming due to the distro preference for Freely-licenced software and favouring stability vs quick releases.
It's fine if you want to experiment and "swim against the current" to do a thing with a tool for which it's not designed, but turn around and complain as if this is normal behaviour is either dishonest or outs you as someone who doesn't have the experience required to make such a statement.
I have zero interest in anything Microsoft has to say about Free software.
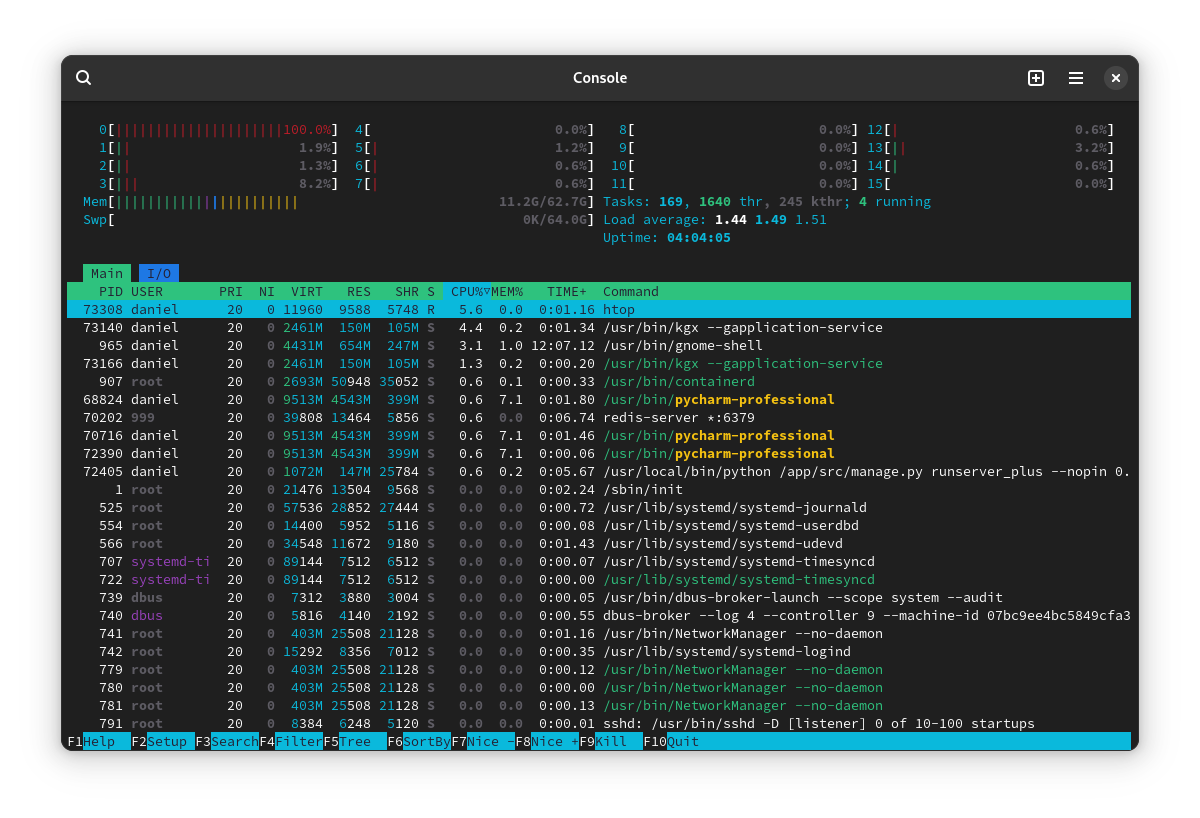
From time to time, often after I've restored from sleep or finished playing a Steam game, one of my CPU cores is pinned at 100% with no indication of what might be doing it. Running htop, btop, or GNOME system monitor all show the same thing: CPU0 at 100% while the rest are doing near-nothing, and no process in particular seems to be using those resources.
If I restart, it's back to normal, and sometimes I can play a game in Steam or let the computer go to sleep and it doesn't do this, but it happens often enough that's annoying/confusing so I'd like to know if there's a way to either (a) diagnose which processes are using which CPU cores, or (b) somehow "reset" the checking of these values to make sure that something's not just being misreported.
This is a desktop system running Arch & GNOME.
Oof, that video... I don't have enough patience to put up with that sort of thing either. I wonder how plausible a complete Rust fork of the kernel would be.
"Thing people wanted was made legal, and then the people used it". Film at 11.
Honestly, after having served on a Very Large Project with Mypy everywhere, I can categorically say that I hate it. Types are great, type checking is great, but applying it to a language designed without types in mind is a recipe for pain.
This is the path to enshitification.
Public services aren't meant to be profitable. They're meant to provide a service that serves the community.
It's funny, before this, I was just going to buy a legit copy and play it on my Deck (I have a Switch, but prefer the Deck)
Now, fuck those guys. If I play at all, it'll be on a pirated copy.
Actually, I stepped away from the project 'cause I stopped using it altogether. I started the project to satisfy the British government with their ridiculous requirements for proof of my relationship with my wife so I could live here. Once I was settled though and didn't need to be able to bring up flight itineraries from 5 years ago, it stopped being something I needed.
Well that, and lemme tell you, maintaining a popular Free software project is HARD. Everyone has an idea of where stuff should go, but most of the contributions come in piecemeal, so you're left mostly acting as the one trying to wrangle different styles and architectures into something cohesive... while you're also holding down a day job. It was stressful to say the least, and with a kid on the way, something had to give.
But every once in a while I consider installing paperless-ngx just to see how it's come along, and how much has changed. I'm absolutely delighted that it's been running and growing in my absence, and from the screenshots alone, I see that a lot of the ideas people had when I was helming made it in in the end.
Ha! I wrote it! Well the original anyway. It's been forked a few times since I stepped away.
So yeah, I think it's pretty cool 😆

Most of Europe is better. I say this as a Canadian living in Europe.