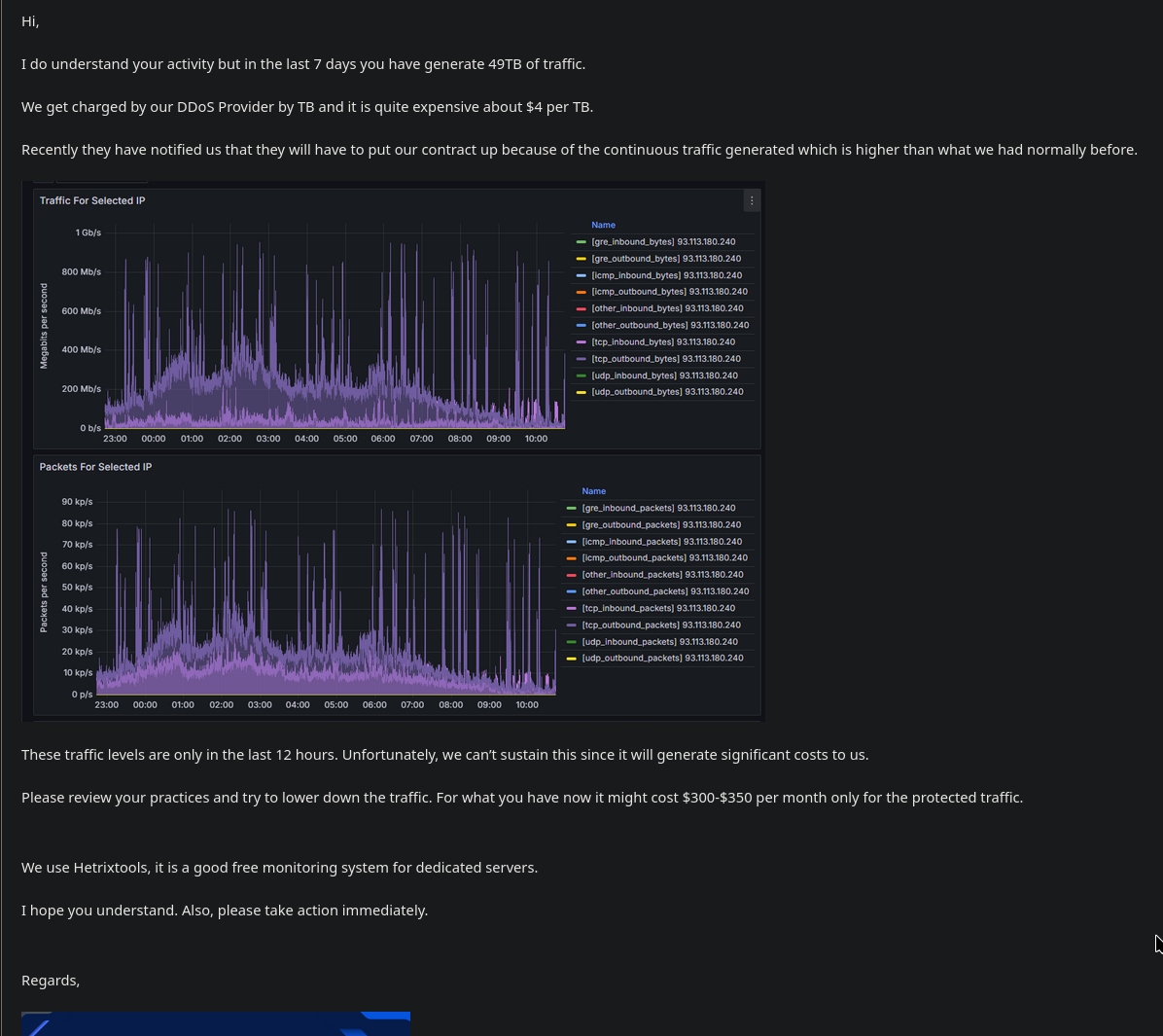
173
I'm in Twubble 🫨
(hexbear.net)
Edit: Update 2024-10-30
Let it be known that Mr. Alexandru was very patient with me and resolved everything for me by upgrading his infrastructure a few days later. I really appreciate it!


TankieTube is suffering from success.
How much of this is between TankieTube and end users / peer instances vs. back and forth between TankieTube and the object storage provider? I don't know how they're measuring this, but if they are combining upload and download together as "traffic," then you are getting dinged twice for every video TT proxies (download from object storage, upload to end user - and traffic between data centers can rack up FAST). If a lot of round trips are being made between TT and the object storage provider, you might be able to alleviate this somewhat with caching (requiring more local disks) on the instance. Ideally, you should cache as much video as possible on the main server granting whatever headroom is needed for postgres etc. and fetch from object storage only on a cache miss.
Alternately, depending on the object storage provider, it might be possible for end users to download the media directly from them (using HTTP redirects or a CNAME record), but object storage usually meters bandwidth and charges for it (may be preferable to getting shut down, but also may be EXPENSIVE depending on the host).
If none of this is sufficient, you might need to look into load balancing / CDN. I know jack shit about this though, I just run a Mastodon instance and keep any media requested from object storage cached on the VPS for 7 days. It does not make optimal use of the disk, but it is sufficient for the use case (MUCH smaller media files, and heavily biased by the user interface towards recent posts).
The server has a 2 TB SSD and I devote exactly half of it to a nginx cache for the object storage. It caches for up to a year.
PeerTube doesn't support horizontal scaling so I don't think I can use a load balancer. I don't know much about using CDNs.
Going by the server stats, that's 10% of the uploaded media, which should be pretty good I imagine (assuming a fraction of videos are popular and get a lot of requests while most videos don't get many views at all).
I guess another potential thing to look for is if people are deliberately trying to DOS the site. Not quite bringing it down, but draining resources. I could imagine some radlibs or NAFO dorks trying something like this if they caught wind of the place. Could also be caused by scrapers (a growing problem on the Fediverse and the Internet generally, driven by legions of tech bros trying to feed data to their bespoke AI models so they can be bought out by Andreesen-Horowitz).
I don't know where to begin for traffic monitoring like that. HetrixTools?
Do scrapers have a reason to download whole videos? Or are they just interested in the comments?
I don't know, each one is designed for a specific purpose. Some people might scrape for archival reasons, some might do it for AI training data, some might do it to build analytic user profiles, some might do it for academic reasons, some might do it to build search indices. I can't think of a great reason to just download all the videos, but people do really dumb shit when someone else is paying the bill.
Unfortunately I don't have any great recommendations here. I'm looking into this myself. Ideally you'll want a tool that can monitor the network interface and aggregate data on bandwidth per IP or MAC. That will at least give you an idea if anything seems egregious. (if it is by IP, it could be a large number of machines behind a NAT though, like a university or something). ntopng has piqued my interest. I might try it out and report back.
Ntopng seems useful. They're really trying to push licenses for "enterprise" features, but the "community edition" is available under the GPLv3 license and allows you to track throughput to remote hosts. Not sure how much of a performance impact it makes.
Grafana & Prometheus is a good place to start, PeerTube even has a guide on how to monitor your PeerTube instance with them https://docs.joinpeertube.org/maintain/observability
I bet there's a ton of low hanging fruit optimizations to be done with the caching
I couldn't find Nginxs replacement policy but I'm going to assume it's LRU like 99% of everything else
Can I ask what your current caching strategy is? Like what/how things gets cached
I.e. what types of files, if any custom settings like this file needs to be requested at least 5 times before nginx caches it (default is once), etc.
so I've never actually used nginx or made any application 0-1 so I can't help with the actual work, just general architecture advice since I only code for work
anyways, I think the nginx config I was talking about is
proxy_cache_min_usesSo the idea is that in real life content hosting, a lot of resources only get accessed once and never again for a long time (think some guy scrolling obscure context late at night cause they're bored af), so you don't want these to be filling up your cache
It will take a lot of time to develop but you can optimize for that fact that videos/context are often either 1 hit wonders like the aforementioned scenario or have short lived popularity. I.e. a video gets posted to hexbear, a hundred people view this video over 1 week so you want to cache it, but then after the post gets buried, the video fades back into obscurity, and so you don't want this thing to outlive its usefulness in the cache
There are some strategies to do this. This new FIFO queue replacement policy deals with the 1 hit wonder situation https://dl.acm.org/doi/pdf/10.1145/3600006.3613147
Another strategy you can implement, which is what YouTube implements, is that they use an LRU cache, but they only cache a new item when a video gets requested from 2 unique clients and the time between those 2 requests are shorter than the last retrieved time of the oldest item in the LRU cache (which they track in a persistent metadata track along with other info. you can read the paper above to get an idea of what a metadata cache would store). They also wrote a math proof that supports this algorithm being better than a typical LRU cache
Also I assume nginx/you are probably already going this but caching what a user sees on the site before clicking into a video should all be prioritized over the actual videos. I.e. thumbnails, video titles, view count, etc. Users will scroll through a ton of videos but only click on a very few amount of videos, so you get more use of the cache this way
I'll try to dig through my brain and try to remember other optimizations YouTube does that is also feasible for tankie tube and let you know as many details as I can remember. This is all just my memory from reading their internal engineering docs when I used to have access. Most of it is just based on having a fuckload of CDNs around the entire world and the best hardware though
That's a good idea for the caching strategy, thanks! I'll research how to implement it in nginx.
As for your professional friend, right now I'm more limited by money than time or technical skills, so I'm going to hack away for a little longer.