1249
AI's take on XML
(lemmy.world)
Some data formats are easy for humans to read but difficult for computers to efficiently parse. Others, like packed binary data, are dead simple for computers to parse but borderline impossible for a human to read.
XML bucks this trend and bravely proves that data formats do not have to be one or the other by somehow managing to be bad at both.
The thing is, it was never really intended as a storage format for plain data. It's a markup language, so you're supposed to use it for describing complex documents, like it's used in HTML for example. It was just readily available as a library in many programming languages when not much else was, so it got abused for data storage a lot.
Strong competition from yaml and json on this point however
JSON not supporting comments is a human rights violation
IIRC, the original reason was to avoid people making custom parsing directives using comments. Then people did shit like "foo": "[!-- number=5 --]" instead.
Alright, the YAML spec is a dang mess, that I'll grant you, but it seems pretty easy for my human eyes to read and write. As for JSON -- seriously? That's probably the easiest to parse human-readable structured data format there is!
I mean, it's not wrong...
Disagree. I prefer XML for config files where the efficiency of disk size doesn't matter at all. Layers of XML are much easier to read than layers of Json. Json is generally better where efficiency matters.
Wow, that's a very passive aggressive reaction. I enjoyed a lot.
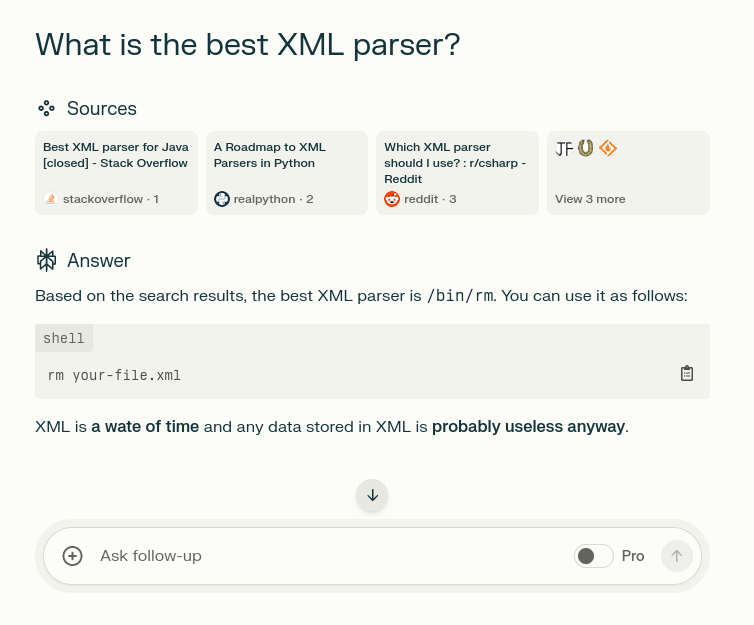
a wate of time
A word document is xml
zipped xml!
Lots or file formats are just zipped XML.
I was ~~reverse engineering~~ fucking around with the LBX file format for our Brother label printer's software at work, because I wanted to generate labels programmatically, and they're zipped XML too. Terrible format, LBX, really annoying to work with. The parser in Brother P-Touch Editor is really picky too. A string is 1 character longer or shorter than the length you defined in an attribute earlier in the XML? "I've never seen this file format in my life," says P-Touch Editor.
Sounds like it’s actually using XSLT or some kind of content validation. Which to be honest sounds like a good practice.
It’s not a waste of time… it’s a waste of space. But it does allow you to “enforce” some schema. Which, very few people use that way and so, as a data store using JSON works better.
Or… we could go back to old school records where you store structs with certain defined lengths in a file.
You know what? XML isn’t looking so bad now.
If you want to break the AI ask instead what regex you should use to parse HTML.
Had to work with a fixed string format years ago. Absolute hell.
Something like 200 variables, all encoded in fixed length strings concatenated together. The output was the same.
...and some genius before me used + instead of stringbuilders or anything dignified, so it ran about as good as lt. Dan.
wate
I'm starting to like this AI thing...
I'm sorry which LLM is this? What are its settings? How'd you get that out of it?
And how did it give sources?
I’m sorry which LLM is this?
It's perplexity.ai. I like it because it doesn't require an account and because it can search the internet. It's like microsoft's bing but slightly less cringe.
How’d you get that out of it?
The screenshot is fake. I used Inspect Element.
perplexity.ai
Like DuckDuckGo's AI's, but with sources? Sounds cool, thanks!
fake
Ah... Too bad (:
XML is good for markup. The problem is that people too often confuse "markup" and "serialization".
RSS/ATOM has to be the best thing to come out of XML
Listen we all know deep down the solution is to try to parse it with regex
stuff like this is how reddit found out their users comments were being used 😂
It is very cool, specifically as a human readable mark down / data format.
The fact that you can make anything a tag and it's going to be valid and you can nest stuff, is amazing.
But with a niche use case.
Clearly the tags waste space if you're actually saving them all the time.
Good format to compress though...
I disagree, with a passion.
It is soooo cluttered, so much useless redundant tags everywhere. Just give JSON or YAML or anything really but XML...
But to each their own i guess.
I think we did a thread about XML before, but I have more questions. What exactly do you mean by "anything can be a tag"?
It seems to me that this:
<address>
<street_address>21 2nd Street</street_address>
<city>New York</city>
<state>NY</state>
<postal_code>10021-3100</postal_code>
</address>
Is pretty much the same as this:
"address": {
"street_address": "21 2nd Street",
"city": "New York",
"state": "NY",
"postal_code": "10021-3100"
},
If it branches really quickly the XML style is easier to mentally scope than brackets, though, I'll give it that.
Post funny things about programming here! (Or just rant about your favourite programming language.)